Bayes là gì? Phân loại văn bản bằng Bayes
1. Giới thiệu phương pháp phân loại đơn giản bằng Bayes.
Phương pháp phân loại Bayes đơn giản sử dụng trong trường hợp mỗi ví dụ được cho bằng tập các thuộc tính <x1, x2, …, xn> và cần xác định nhãn phân loại y, y có thể nhận giá trị từ một tập nhãn hữu hạn C. Trong giai đoạn huấn luyện, dữ liệu huấn luyện được cung cấp dưới dạng các mẫu <xi, yi>. Sau khi huấn luyện xong, bộ phân loại cần dự đoán nhãn cho mẫu mới x
Theo lý thuyết học Bayes, nhãn phân loại được xác định bằng cách tính xác suất điều kiện của nhãn khi quan sát thấy tổ hợp giá trị thuộc tính <x1, x2, …, xn>. Thuộc tính được chọn, ký hiệu CMAP là thuộc tính có xác suất điều kiện cao nhất (MAP là viết tắt của maximum a posterior), tức là:
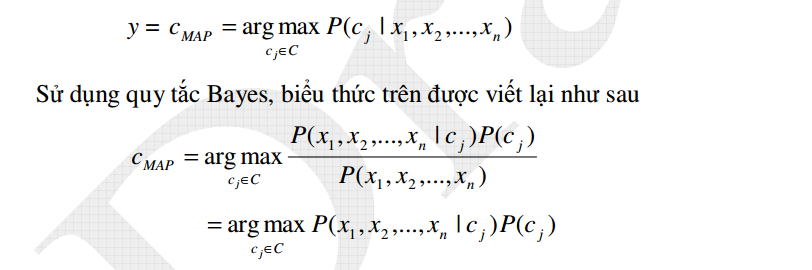
Hai thành phần trong biểu thức trên được tính từ dữ liệu huấn luyện. Giá trị P(cj) được tính bằng tần suất quan sát thấy nhãn cj trên tập huấn luyện, tức là bằng số mẫu có nhãn là cj chia cho tổng số mẫu.
Việc tính P(x1, x2 ,…, xn | cj ) khó khăn hơn nhiều. Vấn đề là số tổ hợp giá trị của n thuộc tính cùng với nhãn phân loại là rất lớn khi n lớn. Để tính xác suất này được chính xác, mỗi tổ hợp giá trị thuộc tính phải xuất hiện cùng nhãn phân loại đủ nhiều, trong khi số mẫu huấn luyện thường không đủ lớn.
Với giả thiết về tính độc lập xác suất có điều kiện, có thể viết:
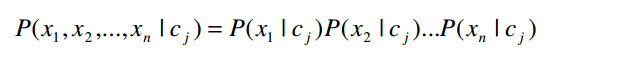
Tức là xác suất đồng thời quan sát thấy các thuộc tính bằng tích xác suất điều kiện của từng thuộc tính riêng lẻ. Thay vào biểu thức ở trên, ta được bộ phân loại Bayes đơn giản (có đầu ra ký hiệu là cNB) như sau:
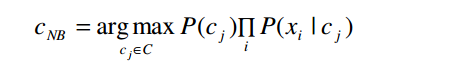
Trong đó, P(xi | cj ) được tính từ dữ liệu huấn luyện bằng số lần xi xuất hiện cùng với cj chia cho số lần cj xuất hiện. Việc tính xác suất này đòi hỏi ít dữ liệu hơn nhiều so với tính P(x1, x2,…, xn | c j ) .
Quá trình học Bayes đơn giản là quá trình tính các xác suất P(cj) và các xác suất điều kiện P(xi | c j ) bằng cách đếm trên tập dữ liệu. Học Bayes đơn giản không đòi hỏi tìm kiếm trong không gian các bộ phân loại như đối với trường hợp học cây quyết định.
2. Vấn đề tính xác xuất thực tế:
Phân loại Bayes đơn giản đòi hỏi tính các xác suất điều kiện thành phần P(xi | c j ) . Xác suất này được tính bằng nc / n, trong đó nc số lần xi và cj xuất hiện đồng thời trong tập huấn luyện và n là số lần c j xuất hiện.
Trong nhiều trường hợp, giá trị nc có thể rất nhỏ, thậm chí bằng không, và do vậy ảnh hưởng tới độ chính xác khi tính xác suất điều kiện. Nếu nc = 0, xác suất điều kiện cuối cùng sẽ bằng không, bất kể các xác suất thành phần khác có giá trị thế nào.
Để khắc phục vấn đề này, một kỹ thuật được gọi là làm trơn thường được sử dụng. Trong trường hợp đơn giản nhất, ta tính P(xi | c j ) = (nc + 1) /( n + 1). Trong trường hợp chung, có thể sử dụng công thức được làm trơn sau:
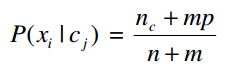
Trong đó p là xác suất tiền nghiệm của xi và m là tham số cho phép xác định ảnh hưởng của p tới công thức. Nếu không có thêm thông tin gì khác thì xác suất tiền nghiệm thường được tính p = 1 / k, trong đó k là số thuộc tính của thuộc tính Xi.
3. Ứng dụng bayes trong phân loại văn bản.
Phân loại văn bản tự động là bài toán có nhiều ứng dụng thực tế. Trước tiên, cho một tập huấn luyện bao gồm các văn bản. Mỗi văn bản có thể thuộc vào một trong C loại khác nhau (ở đây ta không xét trường hợp mỗi văn bản có thể thuộc vào nhiều loại khác nhau). Sau khi huấn luyện xong, thuật toán phân loại nhận được văn bản mới và cần xác định phân loại cho văn bản này. Ví dụ, với các văn bản là nội dung thư điện tử, thuật toán có thể phân loại thư thành “thư rác” và “thư bình thường”. Khi huấn luyện, thuật toán học được cung cấp một tập thư rác và một tập thư thường. Sau đó, dựa trên nội dung thư mới nhận, bộ phân loại sẽ tự xác định đó có phải thư rác không. Một ứng dụng khác là tự động phân chia bản tin thành các thể loại khác nhau, ví dụ “chính trị”, “xã hội”, “thể thao”.v.v. như trên báo điện tử.
Phân loại văn bản tự động là dạng ứng dụng trong đó phân loại Bayes đơn giản và các phương pháp xác suất khác được sử dụng rất thành công. Chương trình lọc thư rác mã nguồn mở SpamAssassin (http:// spamassassin.apache.org) là một chương trình lọc thư rác được sử dụng rộng rãi với nhiều cơ chế lọc khác nhau, trong đó lọc Bayes đơn giản là cơ chế lọc chính được gán trọng số cao nhất.
Sau đây ta sẽ xem xét cách sử dụng phân loại Bayes đơn giản cho bài toán phân loại văn bản. Để đơn giản, ta sẽ xét trường hợp văn bản có thể nhận một trong hai nhãn: “rác” và “không”.
Để sử dụng phân loại Bayes đơn giản, cần giải quyết hai vấn đề chủ yếu: thứ nhất, biểu diễn văn bản thế nào cho phù hợp; thứ hai: lựa chọn công thức cụ thể cho bộ phân loại Bayes.
Cách thông dụng và đơn giản nhất để biểu diễn văn bản là cách biểu diễn bằng “túi từ” (bag-of-word). Theo cách này, mỗi văn bản được biểu diễn bằng một tập hợp, trong đó mỗi phần tử của tập hợp tương ứng với một từ khác nhau của văn bản. Để đơn giản, ở đây ta coi mỗi từ là một đơn vị ngôn ngữ được ngăn với nhau bởi dấu cách. Lưu ý rằng đây là cách đơn giản nhất, ta cũng có thể thêm số lần xuất hiện thực tế của từ trong văn bản. Cách biểu diễn này không quan tâm tới vị trí xuất hiện của từ trong văn bản cũng như quan hệ với các từ xung quanh, do vậy có tên gọi là túi từ. Ví dụ, một văn bản có nội dung “Chia thư thành thư rác và thư thường” sẽ được biểu diễn bởi tập từ {“chia”, “thư”, “thành”, “rác”, “và”, “thường”} với sáu phần tử.
Giả thiết các từ biểu diễn cho thư xuất hiện độc lập với nhau khi biết nhãn phân loại, công thức Bayes đơn giản cho phép ta viết:
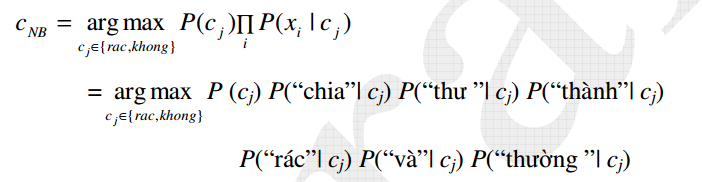
Các xác suất P(“rác”| cj) được tính từ tập huấn luyện như mô tả ở trên. Những từ chưa xuất hiện trong tập huấn luyện sẽ bị bỏ qua, không tham gia vào công thức.
Cần lưu ý rằng cách biểu diễn và áp dụng phân loại Bayes đơn giản cho phân loại văn bản vừa trình bày là những phương án đơn giản. Trên thực tế có rất nhiều biến thể khác nhau cả trong việc chọn từ, biểu diễn văn bản bằng các từ, cũng như công thức tính xác suất điều kiện của văn bản.
Mặc dù đơn giản, nhiều thử nghiệm cho thấy, phân loại văn bản tự động bằng Bayes đơn giản có độ chính xác khá cao. Trên nhiều tập dữ liệu thư điện tử, tỷ lệ phân loại chính xác thư rác có thể đạt trên 98%. Kết quả này cho thấy, mặc dù giả thiết các từ độc lập với nhau là không thực tế, độ chính xác phân loại vẫn của Bayes đơn giản không bị ảnh hưởng đáng kể.
Bài viết này mình trích hoàn toàn từ giáo trình trí tuệ nhân tạo của thầy Từ Minh Phương (Học viên công nghệ bưu chính viễn thông)
Các bạn có thể download bài giảng đầy đủ tại đây
Phần tiếp theo: Chương trình lọc thư rác bằng ngôn ngữ Java
